在智能制造浪潮席卷全球的今天,数据已成为驱动生产、优化决策的核心要素。海量、高速、多样的实时数据洪流,也让许多企业面临采集难、处理慢、应用浅的困境。实时数据处理真的如此棘手吗?一家领先的智能制造企业的成功实践,或许能为我们提供极具价值的参考答案。
一、 实时数据处理的三大核心挑战
在深入案例之前,首先需要明确智能制造场景下实时数据处理的典型难点:
- 数据洪流与系统压力:生产线上的传感器、机器视觉系统、PLC控制器等每时每刻都在产生TB级的数据。传统批处理架构难以承载如此高的吞吐量和低延迟要求,极易导致数据积压与信息滞后。
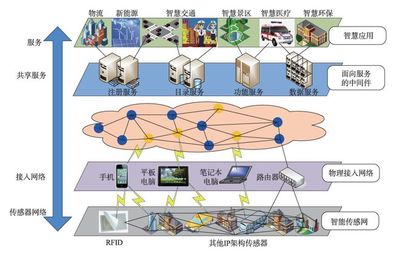
- 数据孤岛与格式异构:企业内生产设备(OT)系统与企业资源计划(ERP)、制造执行系统(MES)等信息技术(IT)系统往往标准不一,协议各异,导致数据难以连通和融合,形成“数据烟囱”。
- 价值挖掘与应用滞后:收集数据不是目的,实时洞察并驱动行动才是关键。如何将实时数据流快速转化为设备预测性维护、工艺参数动态优化、质量实时管控等业务价值,是最大的挑战。
二、 案例剖析:一家智能制造企业的破局之道
某国内高端装备制造企业,同样面临上述挑战。其生产线包含数百台智能设备,每天产生数十亿条数据。过去,质量分析报告需要次日才能生成,设备故障只能事后维修,严重影响了生产效率和产品良率。为此,他们进行了一场彻底的数据服务变革:
1. 架构革新:构建“云-边-端”协同的实时数据管道
* 边缘侧轻量化预处理:在设备侧或车间级部署边缘计算网关,对原始数据进行首次过滤、清洗和压缩,只将关键特征数据和异常事件实时上传,极大减轻了网络和中心系统的负载。
- 平台层流批一体处理:企业引入了先进的流式计算框架(如Apache Flink、Spark Streaming),搭建了统一的实时数据平台。该平台能够同时处理实时数据流和批量历史数据,实现“数据入湖即可用”。
- 云边协同与弹性伸缩:核心模型训练和全局优化在云端进行,再将优化后的算法模型下发至边缘侧执行,实现了计算资源的灵活配置与高效利用。
2. 服务升级:打造场景化的实时数据产品
企业并未止步于技术平台建设,而是将数据能力封装成一项项可被业务部门直接调用的“数据服务”:
- 设备健康度实时预警服务:基于实时振动、温度、电流数据,构建预测性维护模型,提前数小时预警潜在故障,将非计划停机减少70%。
- 生产工艺参数实时优化服务:将实时生产数据与质量检测结果闭环关联,通过机器学习动态调整设备参数,使产品关键指标的一致性提升了15%。
- 全球产线可视化指挥服务:通过数字孪生技术,将全球各工厂的生产状态、订单进度、能耗情况实时映射在统一指挥大屏上,支持管理层进行秒级决策。
3. 组织与文化:建立数据驱动的运营体系
* 成立了由IT、OT和业务专家组成的“数字孪生小组”,跨部门协作,确保数据服务直击业务痛点。
- 建立了“数据即服务”(DaaS)的内部运营模式,业务部门像使用水电一样订阅所需的数据分析结果,激发了全员的用数积极性。
三、 值得学习的核心经验与启示
这家企业的实践为我们提供了清晰的路线图:
- 从“技术项目”到“业务服务”的思维转变:实时数据处理的成功,关键在于以解决具体业务问题为导向,提供开箱即用的数据服务,而非仅仅搭建一个华丽的技术平台。
- “边云协同”是应对实时性挑战的务实架构:合理分配算力,在源头减少无效数据传输,是处理工业海量数据的黄金法则。
- 统一治理是打破数据孤岛的前提:必须建立统一的数据标准、模型和接入规范,这是实现数据融通和实时流转的基石。
- 组织保障是落地的关键:没有跨职能的协同团队和鼓励试错的数据文化,再先进的技术也难以转化为生产力。
###
实时数据处理绝非易事,但它也并非不可逾越的高峰。正如这家智能制造企业所展示的,困难可以通过创新的技术架构、以业务价值为核心的服务设计以及配套的组织变革来系统性地解决。其精髓在于,将“数据处理”这一技术活动,升维为覆盖技术、业务与管理的“数据服务”体系,从而让实时数据真正成为流淌在智能制造血脉中的智慧血液,驱动企业迈向质量、效率与敏捷性的新高度。对于众多仍在探索中的制造企业而言,这条路径无疑具有重要的借鉴意义。