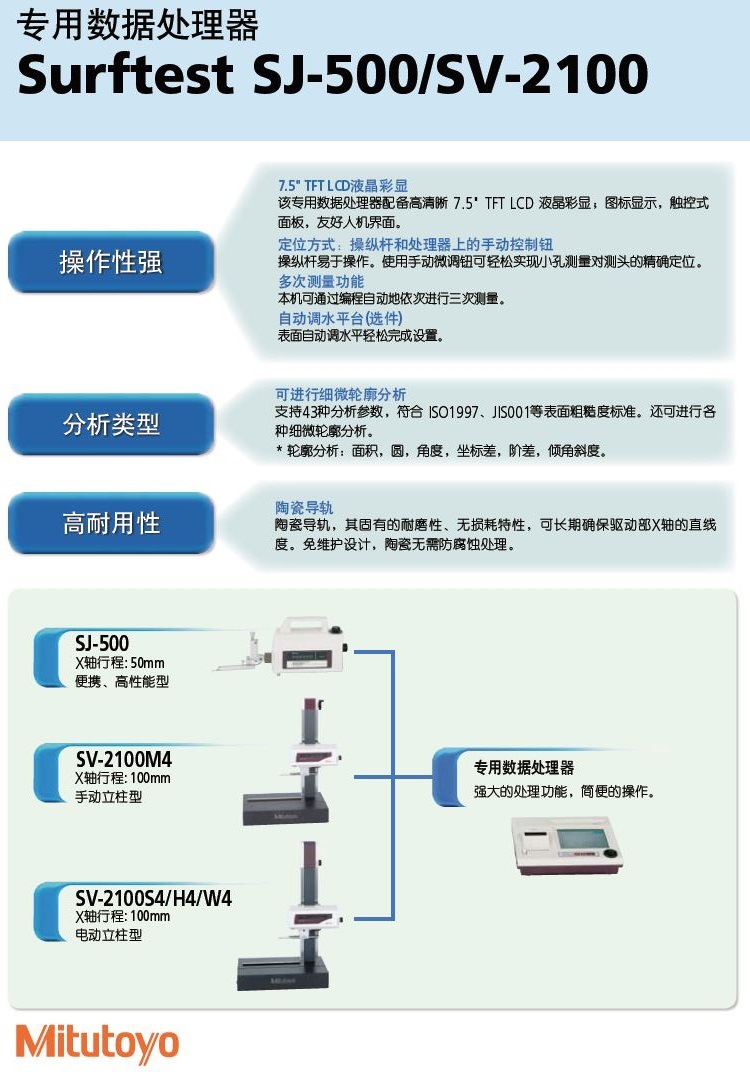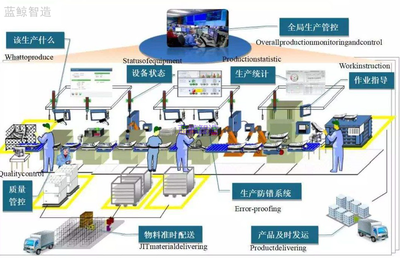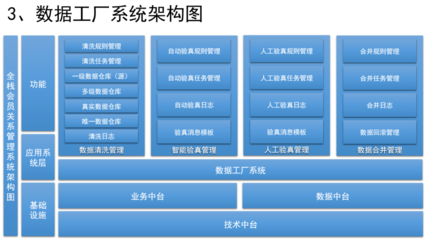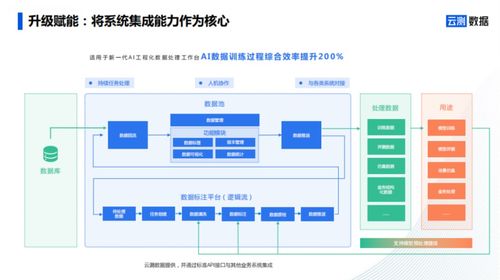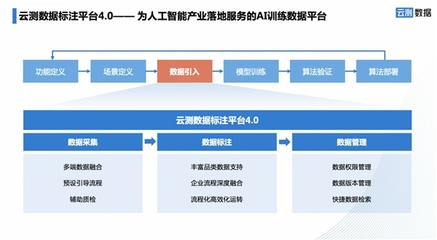
在人工智能迅猛发展的浪潮中,高质量的训练数据已成为驱动AI模型进化的核心燃料。一款宣称能够将数据标注效率提升200%、并降低60%以上成本的数据服务工具横空出世,在业界引发了广泛关注。它究竟有何底气,敢自称“AI训练数据最强工具”?其背后又蕴含着怎样的技术与商业逻辑?
一、 数据瓶颈与行业痛点
当前,AI产业的繁荣与数据标注的“苦力活”形成了鲜明对比。模型精度越高,对训练数据的规模、质量、多样性和标注精度要求就越高。传统的数据处理方式面临几大核心挑战:人工标注成本高昂且效率低下,一致性难以保证;复杂场景(如自动驾驶的3D点云、医疗影像的病灶分割)的标注门槛极高;数据隐私与安全合规要求日益严格。这些痛点严重制约了AI项目的研发速度与规模化落地。
二、 破局之匙:技术驱动的智能化数据服务
这款引发热议的工具,其核心突破在于将前沿AI技术深度融入数据生产的全链路,实现了从“人海战术”到“人机协同”乃至“智能自动化”的范式转变。
- 智能预标注与自动增强:工具内置了经过预训练的强泛化性模型,能够对原始数据进行初步的智能识别与标注(预标注),标注员只需进行修正和审核,工作量大幅减少。它能自动进行数据清洗、去重、增强(如旋转、裁剪、添加噪声),有效扩充高质量数据集。
- 复杂任务专用引擎:针对文本、语音、2D/3D图像、视频等不同模态数据,以及实体识别、情感分析、目标检测、语义分割等不同任务,工具提供了高度优化的专用标注界面与算法辅助,极大降低了复杂标注的操作难度。
- 全链路质量管理与协同平台:它不仅仅是一个标注工具,更是一个项目管理平台。内置的质量控制算法能实时监测标注一致性,智能分配难例复审。云端协同工作流使得全球分布的标注团队能够无缝协作,项目管理透明高效。
- 隐私计算与合规保障:采用联邦学习、差分隐私、数据脱敏等技术,确保原始数据不出域,或在严格加密环境下进行处理,满足了金融、医疗等行业对数据安全的严苛要求。
正是这些技术的深度融合,使得“效率提升200%”和“成本降低60%”并非夸大其词。效率提升源于自动化对人工的替代与辅助;成本降低则综合了人力节省、流程优化、错误减少及数据利用率提升等多重因素。
三、 深远影响与未来展望
这款工具的出现,标志着互联网数据服务正从劳动密集型向技术密集型升级。它的影响是深远的:
- 对AI研发者:大幅降低了获取高质量数据的门槛与周期,让初创公司和小团队也能训练出高性能模型,加速创新试错。
- 对数据服务行业:推动了行业向更高附加值、更技术驱动的方向演进,促使传统标注企业进行技术升级。
- 对AI产业生态:通过提供更优质、更经济的“数据养料”,促进更大规模、更复杂的AI应用落地,形成良性循环。
最强工具的称号也需要经受时间与复杂场景的考验。未来的竞争将集中在算法的泛化能力、对长尾场景和极端案例的处理水平、以及对多模态融合标注的支持程度上。数据服务的终极目标,是成为AI基础设施中如水电般可靠、高效的一环。
结论而言,这款以惊人效能数据吸引眼球的工具,其真正的“来头”在于它代表了数据生产领域的智能化革命。它不仅是提升效率的利器,更是解放AI生产力、推动产业整体跃迁的关键拼图。在数据决定AI高度的时代,拥有这样的“最强工具”,无疑意味着抢占了发展的制高点。